LLMs Misunderstanding Categories
Although our optimal settings have significantly improved LLMs' reliability, it is difficult to eliminate all false alerts. Figure 1 illustrates the distribution of various misunderstanding types across different LLMs. This analysis highlights the prevalent errors and their frequency within each evaluated model.
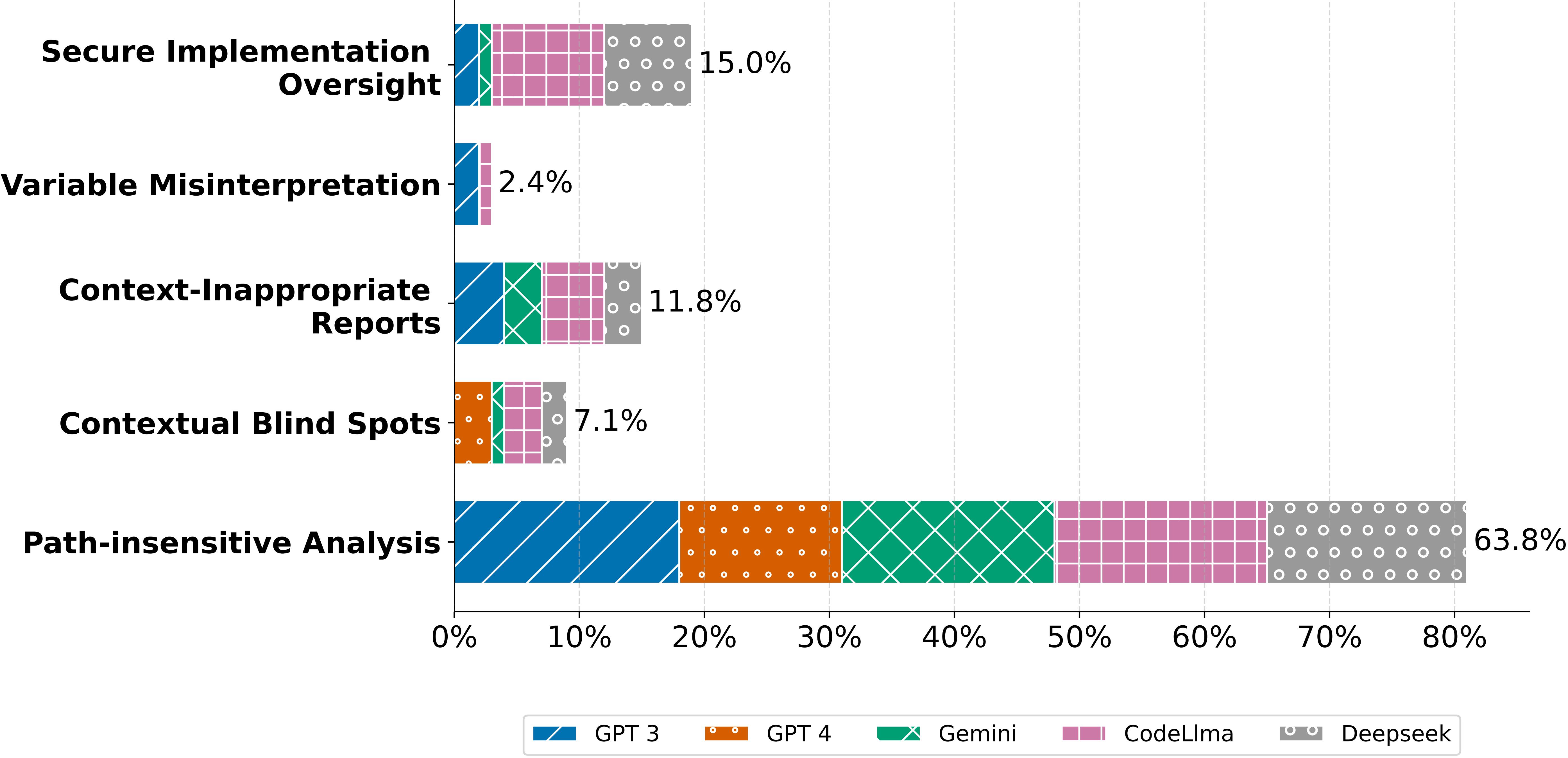
The data reveals a notable similarity in the types of misunderstandings generated by different LLMs. For instance, three distinct categories of errors are commonly produced by four of the evaluated LLMs. Particularly, open-source LLMs such as CodeLlama and DeepSeek, which are characterized by having fewer parameters, demonstrate a higher propensity for incorrect analyses, contributing to 27.6% and 22.0% of FP alerts, respectively. In contrast, models from the GPT series exhibit a more detailed analytical approach, which, however, leads to frequent misclassifications in variable interpretation.
A primary category of misunderstanding involves path-insensitive analysis, where all five LLMs consistently report false positives. This error is specifically prevalent in a test case family within CryptoBench, which introduces a vulnerable cryptographic operation into the code and subsequently replaces it with a secure alternative. Despite the secure nature of the alternative, all LLMs focus on the usage of the initial vulnerable cryptographic operation, resulting in FP alerts.
In several instances, advanced models like GPT and Gemini have demonstrated some capability to discern the logical sequence of changes, yet they still suggest that the initial operation should be removed even though it is not executed. This observation indicates LLMs' potential for path-sensitive analysis, which requires sophisticated configurations in specific scenarios.