SAT Comparison
Figure 1 presents a detailed comparison of detection precision and recall between LLMs and SATs across various benchmarks, highlighting the fluctuating performance of SATs on different benchmarks.
Figure 1: Detection Performance Comparison between LLMs and SATs Across Benchmarks.
In manually-crafted benchmarks, SATs generally exhibit lower recall than LLMs due to two primary factors:
- SATs struggle to detect perturbed test cases from the MASC benchmarks, with CryptoGuard, CogniCryptSAST, and SpotBugs detecting only 11, 9, and 22 GTMs out of 37 cases, respectively.
- The rigidity of SAT rules often leads to numerous irrelevant alerts, which are categorized as false positives in our analysis.
While CryptoGuard and SpotBugs achieve precision comparable to that of DeepSeek and Gemini, they fall slightly behind the GPT series. Moreover, CogniCryptSAST's lower precision can be attributed to its expansive rule set, which often mandates unnecessary operations[1].
In real-world benchmarks, LLMs generally exhibit greater precision than SATs due to their deeper comprehension of the security context, as elucidated in Section 3.2.
While certain SATs may identify a larger number of GTMs compared to some LLMs, this is achieved at the cost of precision. These SATs tend to flag any non-deterministic operations as insecure, leading to false positives and hindering the ability to provide meaningful root cause analysis. Consequently, all SATs demonstrate lower overall accuracy than LLMs.
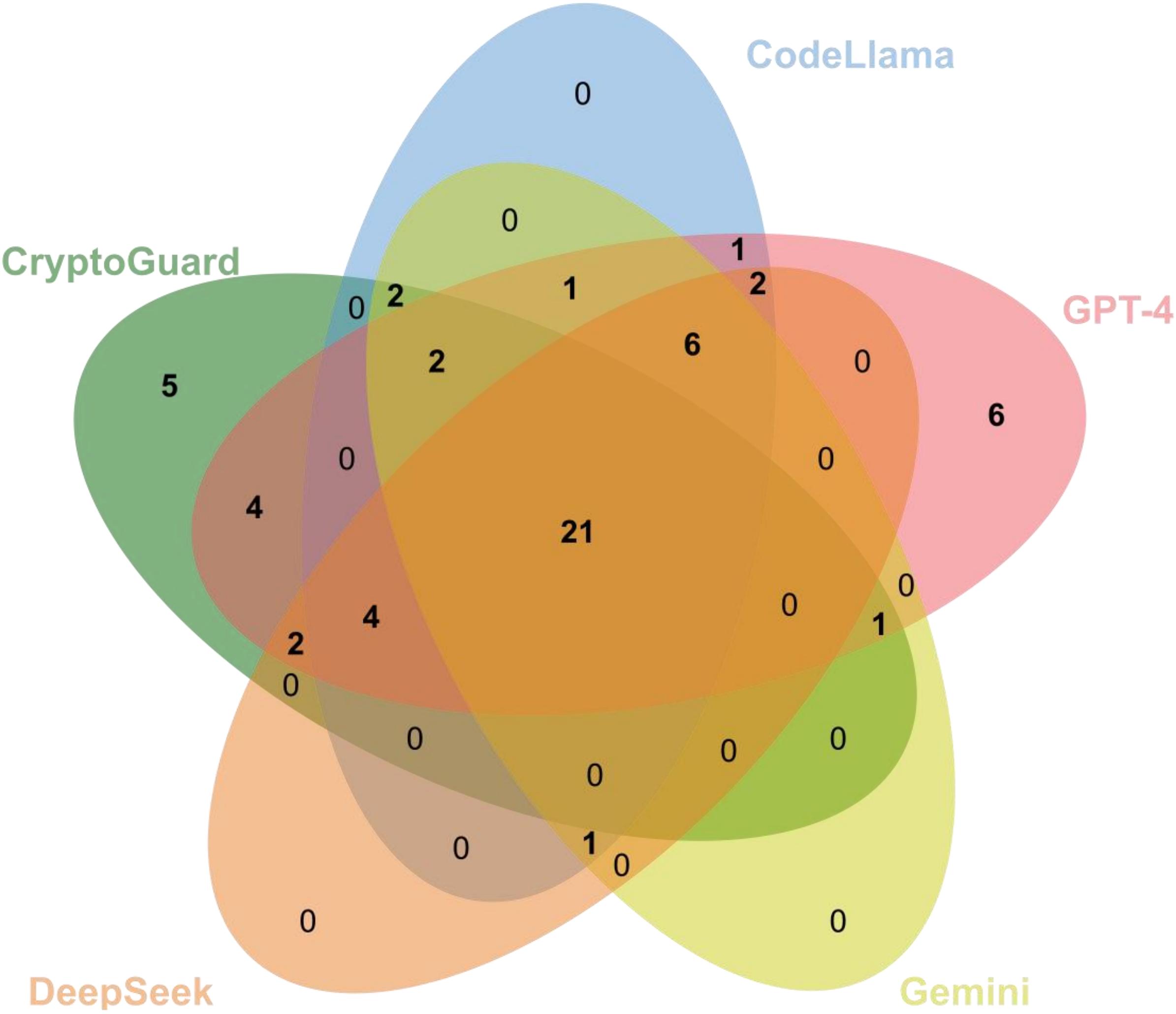
Figure 2: Venn Plots of the Misuse Detected by LLMs and CryptoGuard on the Apache Benchmarks.
Figure 2 presents a comparison of the unique misuse cases detected by LLMs (under optimal settings) and CryptoGuard, the most effective pattern-based SAT in our evaluation, on the Apache Benchmarks. LLMs collectively identified 17 unique misuse cases, whereas CryptoGuard detected 5.
Of the 5 cases uniquely detected by CryptoGuard, 2 involved multi-hop call chains within long contexts, a scenario where LLMs exhibited inconsistent detection capabilities. The remaining 3 cases pertained to insecure HTTP usage, which was not universally classified as misuse by the LLMs.
However, LLMs also uncovered a significantly larger number of misuse cases compared to CryptoGuard. Notably, GPT-4 identified 5 previously unknown misuses that fell outside the targeted categories of SATs. This observation suggests that both traditional SATs and LLMs possess distinct strengths and limitations in misuse detection.
References
- [1] Detailed reference for Apache Benchmarks (to be provided).