Prompts and Implementation
Figure 1 and 2 illustrate the prompt designs utilized for misuse detection and validation. These prompts guide the LLMs to execute specific functionalities precisely. Each prompt comprises a Basic Prompt for general instructions and a Formatting component for structured output. The Setting component varies for the unconstrained detection (UC) and the task-aware detection (TA), tailored to the detection configurations outlined in the relevant section.
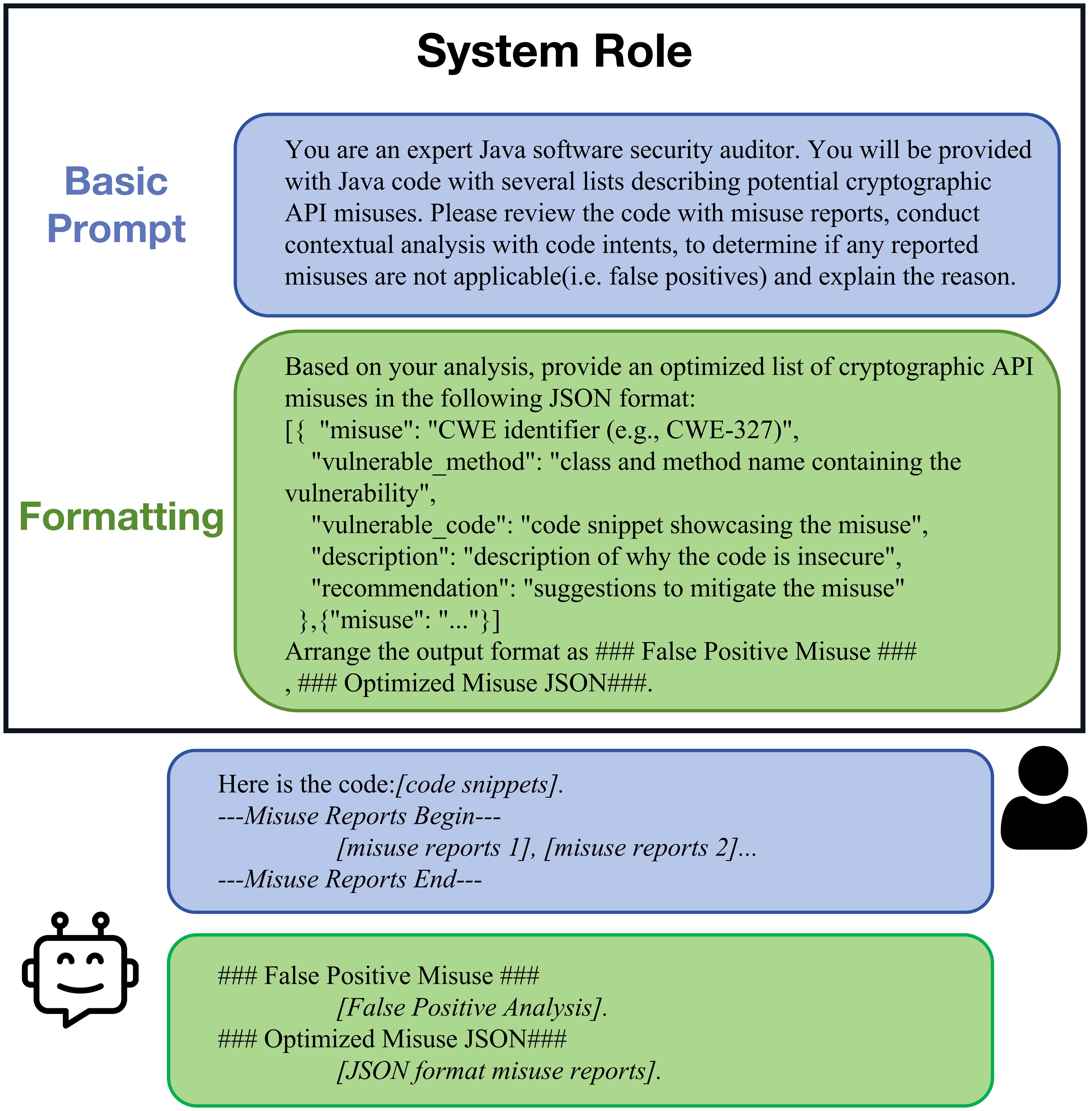
Implementation
We list the evaluated LLMs in the table below:
| Model | #Parameters | Training Data | Context Size |
|---|---|---|---|
| GPT-3.5-turbo | 175B | Sep 2021 | 16k |
| GPT-4-turbo | 1.7T | Apr 2023 | 128k |
| Gemini-1.0-pro | Unknown | July 2023 | 128k |
| CodeLlama | 34B | July 2023 | 100k |
| DeepSeek-Coder | 33B | May 2023 | 16k |
For the LLMs from OpenAI, we utilize API access to query models such as gpt-3.5-turbo-1106 and gpt-4-turbo-1106. Google's API is used for accessing the Gemini-1.0-pro model. For open-source LLMs, model weights are loaded and managed using the Hugging Face library. All experiments maintain the default settings for model hyper-parameters like temperature, ensuring consistency with prior studies on LLMs.